ニキシー管時計を作った話

ニキシー管時計を作った。そのレポート。
仕様
- 24時間表記、時分秒表記
- CD61を使用
- Arduino leonardo制御
- 12V電源にて駆動
- MC340963にて昇圧
- 74141互換IC(K155ID1)使用
コンセプト
ふとニキシー管時計を作りたくなったため、楽に作れることをコンセプトに作った。特にトランス昇圧にトラウマがあったので(昔大型の電解コンデンサを吹っ飛ばした)DC-DC昇圧で、ラフに。調べてみると電流量的にICを使った簡単な昇圧回路で必要電源を作成できそうだったので、それを元に作成した。
制御回路
Arduinoで直接180Vを駆動するわけにもいかないものの、おそらくモーターみたいに電源を別系に分ける必要まではないと思ったので、トランジスタ制御とかでできるかな?とおもったけどそもそもI/Oが全然たりない。
ので、あきらめて2進数をI/OにばらすことができるK155ID1を適当に購入した。ニキシー管の数使用した。計6個。
また、I/Oが足りず一部は下位3bitのみ使っていたりするものの、プルアップされているのか不安定になっているのか、何もつながないと1が入力されている扱いになるため、使わないbitはGNDへ落とす。
回路図
念のため回路図。ただ1ニキシー管分だけ。

基本的に33kの抵抗を挟んでいるだけの構成。これを6本分用意した。
一つだけ、ドットを付けるため、直でGNDに落としたけど、これはさらに流す電流が少ないらしいので、50kを挟んでGNDへ落とした。
パターン
一番気を使ったところ。久しぶりに作ることもあって飛ばすのは控えめにした。プリント基板にするわけではないけど、PCBEを使って引いた。
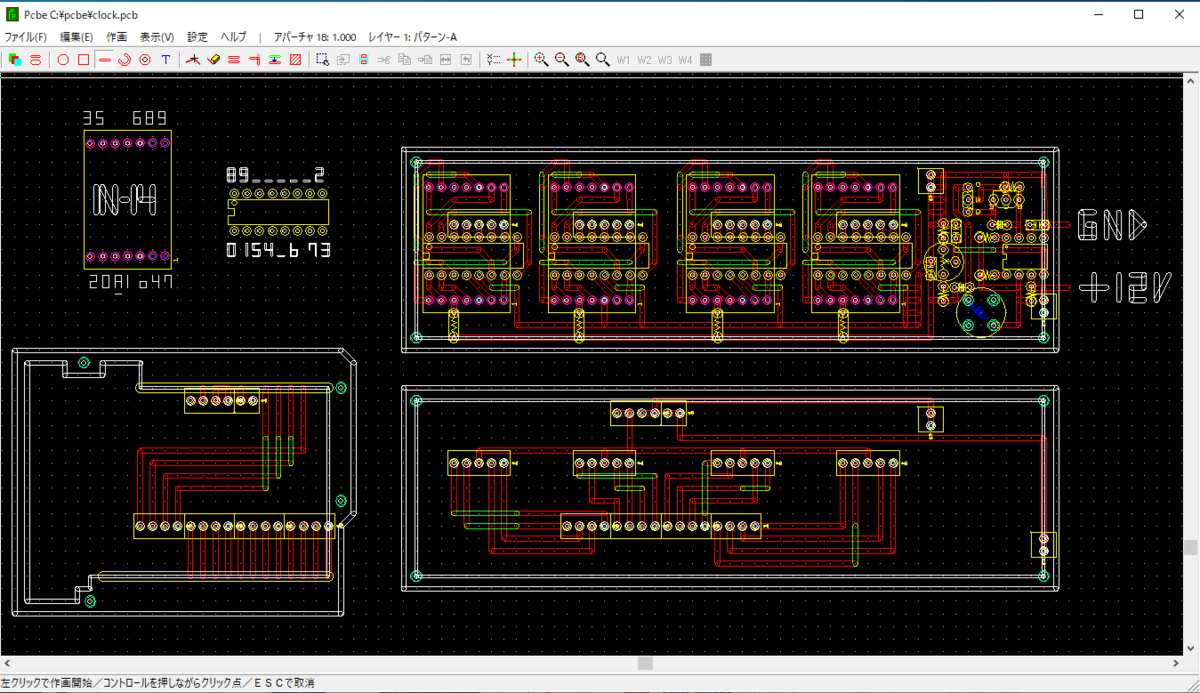
じつは当初4桁のみの予定だったので、2桁分はパターンがないけど、4桁で動作確認終わっていたので気合いで作った。
完成!!

というわけで、土日の2日間で作れたので、興味ある人おすすめです!
ゲート式量子コンピュータが今熱い!〜NISQの紹介〜
mstdn.maud.io Advent Calendar 2018 19日目の記事です(遅刻1日)。昨日はumezouさんでした。
本記事は量子コンピュータに詳しくないWebエンジニア向けに某所で発表したものを記事に落とし込んだものです。
Preskillの2018年の論文、J. Preskill, Quantum Computing in the NISQ era and beyond, Quantum 2, 79 (2018) を元ネタとしていますので、そっちを読んだ方が多分ワクワクします。
- [1801.00862] Quantum Computing in the NISQ era and beyond
- プレスキル "Quantum Computing in the NISQ era and beyond" の翻訳
目次
まとめ
量子コンピュータの概要と一般論
量子コンピュータとは
量子コンピュータとは量子現象を用いて計算するコンピュータのことです。物理法則を直接的に活用するという意味で、今広く使われているデジタルコンピュータよりアナログコンピュータ(OPアンプとか)のほうが近いかもしれません。
量子コンピュータと呼ばれるものは量子現象をどういう演算に活用するかという観点で現在以下の2種類が存在します。
- ゲート式量子コンピュータ
- 量子アニーラ
ゲート式量子コンピュータは汎用量子コンピュータとも呼ばれ古くから知られているものです。暗号を破るなどでSFなどに登場するものもこちらのことです。
他方、量子アニーラは2012年にD-Waveが発表し注目を集め急速に発展した量子コンピュータです。こちらは最適化問題に特化した専用計算機のようなもので国内のWeb系ベンチャーなどで「量子コンピュータやってます!」というときの量子コンピュータはこちらです。
今回は「ゲート式量子コンピュータ」についての記事になります。
量子コンピュータについてよく知られている(と私が思っている)こと
量子コンピュータの実際
以上の印象を踏まえて、実際の量子コンピュータはどうなのでしょうか。
量子コンピュータは古典コンピュータより必ずしも速いわけではない
量子コンピュータは古典よりも必ずしも速いわけではありません。古典でできる計算が全てエミュレーションできると証明はされているものの、古典より速いかどうかは証明されていません。
他方、量子力学の性質によっていくつかの問題は古典コンピュータより速い
どんな場合も速いわけではないですが、前述の素因数分解やまた量子力学のシミュレーションなど古典より速いとされているものは存在します。
量子コンピュータの実用化には原理的に難しい問題を孕んでいる
量子コンピュータの実現が遠そうという印象はその通りです。なぜ量子コンピュータの実現は難しいのでしょうか?それは原理的な問題が存在します。
量子性がはっきりと確認できる環境というのは、ご存知の通り非常にミクロな領域になります。また、そのようなミクロな領域での現象なので非常に雑音などに対して弱い現象とも言えます。そのため、量子状態を保持するためには外界から遮断された環境が必要です。
しかし、量子状態を変化させたり確認するためには干渉する必要があります。状態を変えるということは外界からなんらかの影響を与えて望む変化を起こすことになるためです。当然干渉するためには外界からの遮断が破れてしまい、その際に量子状態が変わってしまったり破れてしまうことが発生するわけです。また、量子ビット同士も干渉しあう必要があります。
つまり、量子状態を保持するためには外界から遮断する必要があるにも関わらず、それを制御するためには外界から影響を与えないといけないという原理的な問題が量子コンピュータの実用化の上で大きな障壁になっているわけです。
なぜ量子コンピュータが強力とされているか
そのように原理的に困難な量子コンピュータですが、なぜ盛んに研究が続いているのでしょうか?それはその困難を乗り越えてでも量子コンピュータが強力だと信じられているからです。
どのような点が強力なのでしょうか。いくつか存在します。
- 古典では困難だが、量子コンピュータで容易に解ける問題が知られている
- 古典では扱えない複雑さを扱える
- 古典的にはいかなる方法を使っても簡単に表現できないとわかっている情報が量子ビットで簡単に表現できることが知られている
- 量子コンピュータを古典で効率的にシミュレートする方法がわかっていない
特に、3番目の「効率的にシミュレートする方法がわかっていない」点が重要です。効率的にシミュレートできないということは、そこに古典を超えるなんらかの優位性が存在すると考えられます。
また、関連していくつか言及すると
古典的に難しい問題と量子的に難しい問題には違いがある
前述のように古典で難しく量子では容易な問題が知られていますが、他方巡回セールスマン問題のようなNP-困難な問題は古典的にも量子的にも難しいようです。
古典はともかく量子が得意とする問題はまだまだ研究の途中なので、それが明らかになってくると古典と量子の計算傾向の違いや使い分けなどが見えてくるかもしれません。
量子コンピュータの歴史
量子コンピュータの研究自体は1980年代から行われています。簡単に以下にまとめます。
- 1950年代:量子力学を計算に使うという考えが提唱される
- 1980年代:量子計算の基本的なコンセプトが考案され、研究が始まる
- 1990年代:Shorのアルゴリズムなどアルゴリズム研究が進む
- 2000年代:ハードウェアの研究が進み始める
- 2010年代:量子アニーラ(D-Wave)が注目を浴び、また量子ゲートも民間等含めた開発が盛んになる
いくつか重要な点があります。
一つは1990年代で、有用なアルゴリズムが開発されたために注目を浴びます。恐らく実現に向けてで言えば、ここが研究が加速する契機です。
次は2011年のD-Waveの発表です。これはゲート式ではないものの商業の量子計算機が出たということで大変注目を集めました。それによって量子コンピュータ界隈全体が活発になりました。ゲート式が今盛り上がっている前提として量子コンピュータ界隈自体が盛り上がっていることは重要です。
その上で、2012年に量子超越性(量子スプレマシー)、古典をゲート式量子コンピュータで超えるという概念が提唱されます。これは2018年にメディア露出し現在民間各社が競って狙っている目標です。具体的に目指すべき目標が設定されたことは一つ契機だと思います。
最後に、2015年にエラー訂正すればまともに使える精度の量子ビットの開発が報告され、開発競争が加速し今に至ります。
NISQについて
NISQとは
NISQとは、Noisy Intermediate-Scale Quantumの略で「50から数百量子ビット程度の中規模でノイズが多い量子コンピュタ」を意味します。
これは、現在から数年後の量子コンピュータを表現するために2018年にPreskillによって提唱されたものです。

NISQがなぜ熱いか
NISQがなぜ熱いかをお話しするにはなぜNISQという概念が作られたかを説明する必要があります。
50量子ビットの障壁
NISQの50量子ビットという数字は非常に重要です。なぜかというと量子超越性が確認できる数字だと考えられているからです。つまり、NISQは初めて古典で計算できなかったことが実現できる量子コンピュータを指し示します。
つまり、古典コンピュータを超越する新しい歴史の幕開けとして、NISQという概念が作られました。NISQによって計算の世界は誰も知らない新時代に入るのです。
新しいアルゴリズム「古典-量子ハイブリッドアルゴリズム」
次に熱いポイントは、実現が見えてきた故に生まれた新しいアルゴリズムの数々です。
これまで量子 vs 古典で語られることの多かった量子コンピュータですが、これらの新しいアルゴリズムの筆頭「古典-量子ハイブリッドアルゴリズム」は量子コンピュータをアクセラレータ的に使用することを念頭に置いたアルゴリズムです。たとえばQAOAやVQEがそれに当たります。
QAOA(量子近似最適化アルゴリズム)は、最小値問題を解くアルゴリズムです。ざっくり説明するとハイパーパラメータの探索は古典で実施し、最小値の計算を量子で実施するアルゴリズムです。
VQE(量子変分アルゴリズム、量子変分固有値ソルバー)は、低エネルギー状態を計算するアルゴリズムです。変分パラメータの探索を古典で実施し、エネルギー期待値を量子で計算します。
また、他に量子RBMなどの量子ディープラーニングも提唱されています。
エンジニア目線で見たNISQ
エンジニア目線でこのNISQの世界を見てみます。
エンジニア目線で見た時、NISQにエンジニアとして関わるのは比較的やりやすい状況が作られています。
一つは、クラウドで使える環境やシミュレーターがすでに存在することです。
このように計算できる環境があるため、アプリケーション開発をすぐにでも始めることができます。
もう一つは、開発環境やフレームワーク、それに伴うサンプルコードなどが存在することです。
ほかにCodeforcesなどの競技プログラミングサイトでQ#を題材にしたコンテストの開催実績などもあります。
また、エンジニアならではの魅力もあります。というのは、NISQでのプログラミングはWebのプログラミングなどとはフェイズが大きく異なる点です。
NISQは前述の通り、多くのアルゴリズムが想定したような大規模な処理系ではなく、非常にチープな処理系です。つまり非富豪的なプログラミングが求められる側面があります。個人的にはこれはかなりチャレンジングでワクワクするシチュエーションだと思っています。
古典の世界で遥か昔の英雄たちがファミコンでドラクエを開発したような、頭を絞るようなプログラミングができる余地があるように思います。絶好の俺TUEEEEEEEEできるフロンティアがここにあります。(妄想)
最後に
以上、かなり偏見の混ざったNISQに関する記事でした。冒頭にもかいているのですが、もしこれを読んで少しでも気になったのであれば元ネタの論文を読んでいただいたほうが正確な内容が理解できると思います。
完全に個人の印象なのですが、珍しい環境かつ今後発展するかもしれない領域で再開発でないエンジニアリングができるという点に大変魅力を感じています。
尤も、私もまだコーディングできるような能力があるわけではないのでこれからですが、興味を持ってくださった方はぜひ一緒に新しい世界へ挑戦しましょう!
明日(遅刻したので今日)はおわたんさんです